 Catégorie
Catégorie by David Mar 04,2025
OpenAI soupçonne que les modèles d'IA profonde de la Chine, nettement moins chers que les alternatives occidentales, ont été développés à l'aide des données d'OpenAI. Cette révélation, associée à la montée rapide de la popularité de Deepseek, a déclenché un ralentissement des marchés boursiers pour les principaux acteurs de l'IA. Nvidia, un fournisseur de GPU clé pour l'IA, a subi la plus forte perte d'une journée dans l'histoire de Wall Street, perdant près de 600 milliards de dollars de valeur marchande. D'autres sociétés comme Microsoft, Meta, Alphabet et Dell ont également connu des baisses importantes.
Le modèle R1 de Deepseek, construit sur le open-source Deepseek-V3, possède des coûts de formation nettement inférieurs (estimés à 6 millions de dollars) et des exigences de calcul par rapport aux homologues occidentaux comme ChatGpt. Bien que cette réclamation soit contestée par certains, elle a alimenté les préoccupations des investisseurs concernant les investissements massifs réalisés par les sociétés technologiques américaines en IA.
OpenAI et Microsoft examinent si Deepseek a violé les conditions d'utilisation d'OpenAI en utilisant la «distillation», une technique qui extrait les données de modèles plus grands pour former des plus petits. OpenAI a confirmé sa conscience de telles tentatives de chinois et d'autres sociétés de tirer parti de la technologie de l'IA en tête. Ils ont souligné leur engagement à protéger leur propriété intellectuelle et collaborent avec le gouvernement américain pour protéger les modèles AI avancés.
David Sacks, le tsar de l'IA du président Trump, soutient la revendication d'extraction des données, prédisant que les principales sociétés d'IA mettront en œuvre des mesures préventives contre la distillation dans les prochains mois.
La situation met en évidence une ironie importante: Openai, lui-même accusé d'utiliser des données sur Internet protégées par le droit d'auteur pour former Chatgpt, accusait désormais Deepseek de pratiques similaires. Cette hypocrisie a été largement notée sur les réseaux sociaux, en particulier la déclaration précédente d'Openai en janvier 2024 que la création de modèles d'IA comme Chatgpt sans matériel protégé par le droit d'auteur est impossible. Cette déclaration a été faite dans une soumission à la Chambre des Lords du Royaume-Uni, faisant écho à leur défense contre les poursuites du New York Times et 17 auteurs alléguant une violation du droit d'auteur. Ces poursuites, ainsi qu'un bureau de droit d'auteur américain de 2018, statuant que l'art généré par l'AI n'est pas le droit d'auteur, souligne les débats juridiques et éthiques en cours entourant les données de formation d'IA.

Comment démarrer les voitures sans clés dans le projet Zomboid
Black Clover M: Les derniers codes de rachat révélés!
Awakening of the Ninjas Codes (janvier 2025)
Roblox libère les codes de table de New Liar
배틀그라운드 pour lancer une nouvelle collaboration avec la marque de bagages américain touristique, à venir le mois prochain
Activision se défend contre le costume Uvalde
Déverrouiller Fortnite XP caché avec des codes de carte exclusifs
Call of Duty: Black Ops 6 Update Retour des zombies controversés Changement

Deep Immersion
Télécharger
Snow Excavator Simulator Game
Télécharger
Pet Shelter: Cat Rescue Story
Télécharger
Bee Robot Car Transform Games
Télécharger
Sniper Target Range Shooting
Télécharger
Zombie Prison Run: Escape Room
Télécharger
Blocky Farm
Télécharger
Gangster 4
Télécharger
Riot Control: Dual Shooter
Télécharger
Sony fait un don de millions à LA Wildfire Relief
Mar 04,2025

L'annonce GTA 6 choque les fans avec des plans de sortie antérieurs
Mar 04,2025
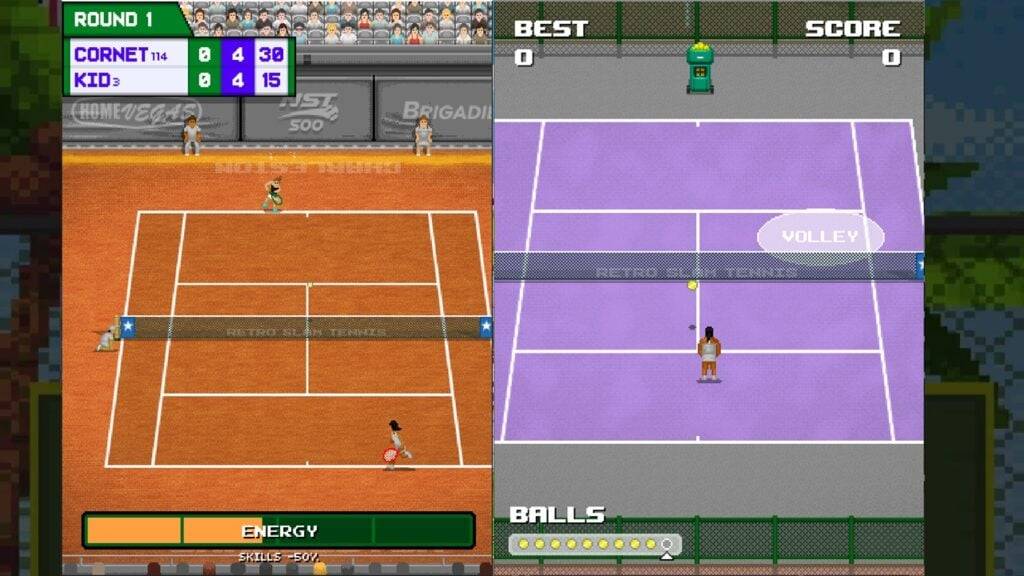
Retro Slam Tennis est le dernier jeu sur Android des créateurs de Retro Bowl
Mar 04,2025
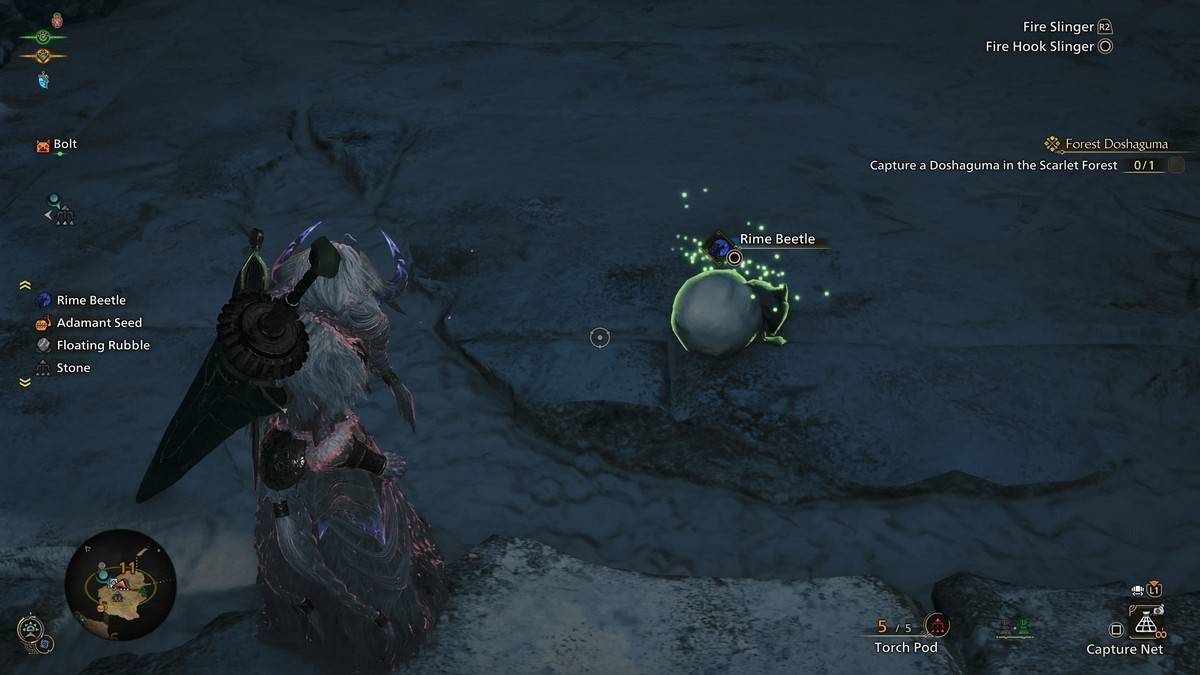
Comment trouver et capturer un scinaire dans le chasseur de monstres sauvages
Mar 04,2025

Blasphématoire est maintenant sorti sur iOS, apportant une action brutale de Grimdark à votre iPhone
Mar 04,2025





