by David Mar 04,2025
Openai sospetta che i modelli di AI Deepseek della Cina, significativamente più economici delle alternative occidentali, siano stati sviluppati utilizzando i dati di Openi. Questa rivelazione, unita al rapido aumento della popolarità di Deepseek, ha scatenato una recessione del mercato azionario per i principali attori dell'IA. Nvidia, un fornitore chiave della GPU per l'IA, ha subito la più grande perdita di un giorno nella storia di Wall Street, perdendo quasi $ 600 miliardi di valore di mercato. Anche altre aziende come Microsoft, Meta, Alphabet e Dell hanno subito cadute significative.
Il modello R1 di DeepSeek, basato sull'apertura open source DeepSeek-V3, vanta costi di allenamento significativamente più bassi (stimati in $ 6 milioni) e requisiti computazionali rispetto alle controparti occidentali come GHATGPT. Sebbene questa affermazione sia contestata da alcuni, ha alimentato le preoccupazioni degli investitori per i massicci investimenti effettuati dalle società tecnologiche americane in AI.
Openai e Microsoft stanno studiando se DeepSeek abbia violato i termini di servizio di Openi impiegando "distillazione", una tecnica che estrae i dati da modelli più grandi per addestrare quelli più piccoli. Openai ha confermato la sua consapevolezza di tali tentativi da parte delle società cinesi e di altre società di sfruttare la tecnologia AI statunitense. Hanno sottolineato il loro impegno a proteggere la loro proprietà intellettuale e stanno collaborando con il governo degli Stati Uniti per salvaguardare i modelli AI avanzati.
David Sacks, Czar AI del presidente Trump, sostiene la pretesa di estrazione dei dati, prevedendo che le principali società di intelligenza artificiale implementeranno misure preventive contro la distillazione nei prossimi mesi.
La situazione mette in evidenza un'ironia significativa: Openai, accusata di usare dati Internet protetti da copyright per formare CHATGPT, sta ora accusando Deepseek di pratiche simili. Questa ipocrisia è stata ampiamente notata sui social media, in particolare data la precedente dichiarazione di Openi nel gennaio 2024 che è impossibile creare modelli di intelligenza artificiale come Chatgpt senza materiale protetto da copyright. Questa affermazione è stata fatta in una sottomissione alla House of Lords del Regno Unito, facendo eco alla loro difesa contro le azioni legali del New York Times e 17 autori che sostengono una violazione del copyright. Queste cause legali, insieme a una sentenza dell'ufficio del copyright statunitense del 2018 che l'arte generata dall'IA non è protetta da copyright, sottolineano i dibattiti legali ed etici in corso che circondano i dati di formazione dell'IA.

Come avviare auto senza chiavi nel progetto zomboid
Black Clover M: I codici di rimborso più recenti rivelati!
Risveglio dei codici Ninjas (gennaio 2025)
Roblox rilascia nuovi codici di bugiardo
PUBG Mobile per lanciare una nuova collaborazione con il marchio di valigie American Tourister, in arrivo il mese prossimo
Activision si difende dalla tuta Uvalde
Sblocca Fortnite XP nascosto con codici mappa esclusivi
Call of Duty: Black Ops 6 Aggiornamento ripristina il cambiamento degli zombi controversi

Deep Immersion
Scaricamento
Snow Excavator Simulator Game
Scaricamento
Pet Shelter: Cat Rescue Story
Scaricamento
Bee Robot Car Transform Games
Scaricamento
Sniper Target Range Shooting
Scaricamento
Zombie Prison Run: Escape Room
Scaricamento
Blocky Farm
Scaricamento
Gangster 4
Scaricamento
Riot Control: Dual Shooter
Scaricamento
Sony che donano milioni a LA Wildfire Relief
Mar 04,2025

L'annuncio GTA 6 Shocks Fans con precedenti piani di rilascio
Mar 04,2025
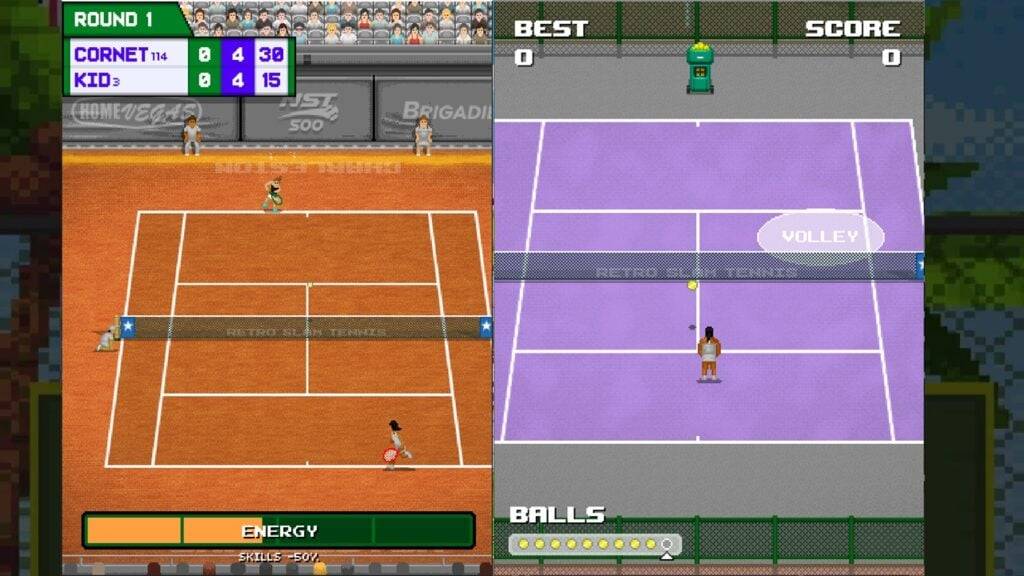
Retro Slam Tennis è l'ultimo gioco su Android dai produttori di retrò ciotola
Mar 04,2025
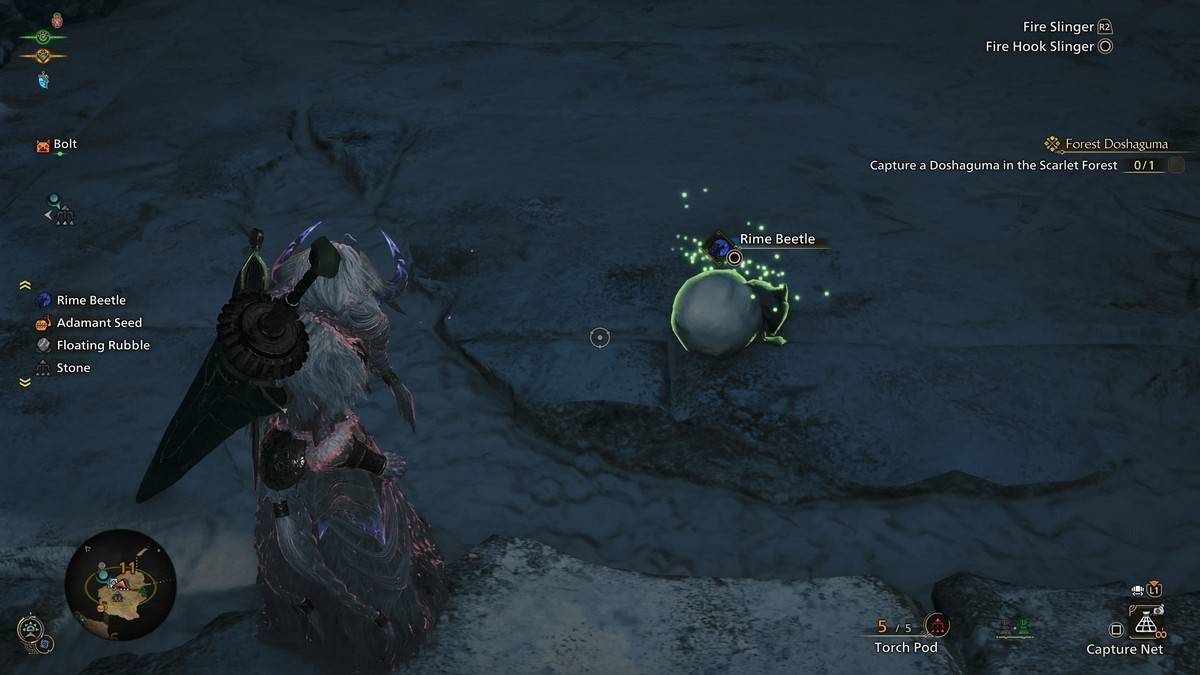
Come trovare e catturare uno scarabeo di rima in mostri cacciatori di caccia
Mar 04,2025

Il blasfemo è ora uscito su iOS, portando un'azione brutale di Grimdark sul tuo iPhone
Mar 04,2025
 Categoria
Categoria 




